
3月1日,DeepSeek官方账号在知乎首次发布《DeepSeek-V3/R1推理系统概览》技术文章,不仅公开了其推理系统的核心优化方案,更首次披露了成本利润率等关键财务数据,引发业内强烈关注。最值得注意的是,DeepSeek表示,如果所有 tokens 全部按照 DeepSeek R1 的定价计算,理论上一天的总收入为 $562,027,成本利润率 545%。
根据DeepSeek官方披露,DeepSeek V3 和 R1 的所有服务均使用 H800 GPU,使用和训练一致的精度,最大程度保证了服务效果。同时,通过动态调整节点资源实现效率最大化。
在最近的24小时里(北京时间 2025/02/27 12:00 至 2025/02/28 12:00),DeepSeek V3 和 R1 推理服务占用节点总和,峰值占用为 278 个节点,平均占用 226.75个节点(每个节点为8个 H800 GPU)。假定 GPU 租赁成本为2美金/小时,总成本为 $87,072/天。
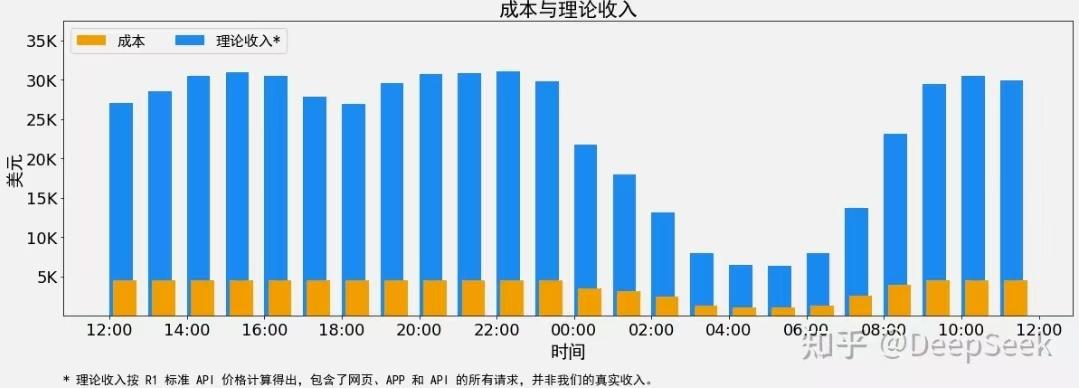
DeepSeek透露,如果所有 tokens 全部按照 DeepSeek R1 的定价计算,理论上一天的总收入为 $562,027,成本利润率 545%。据悉,DeepSeek R1 的定价:$0.14 / 百万输入 tokens (缓存命中),$0.55 / 百万输入 tokens (缓存未命中),$2.19 / 百万输出 tokens。
不过,DeepSeek表示,实际上没有这么多收入,因为 V3 的定价更低,同时收费服务只占了一部分,另外夜间还会有折扣。
此外,DeepSeek还公布了DeepSeek-V3/R1推理系统概述。为实现更大的推理吞吐量与更低的延迟,DeepSeek的方案是使用大规模跨节点专家并行(Expert Parallelism / EP)。首先 EP 使得 batch size 大大增加,从而提高 GPU 矩阵乘法的效率,提高吞吐。其次 EP 使得专家分散在不同的 GPU 上,每个 GPU 只需要计算很少的专家(因此更少的访存需求),从而降低延迟。通过EP增大batch size、将通信延迟隐藏在计算之后,并执行负载均衡,以此应对EP带来的系统复杂性挑战。
文/广州日报新花城记者:张露
广州日报新花城编辑:谢婵







































